

Современные GPU для ИИ и высокопроизводительных вычислений имеют ограниченный объем встроенной высокоскоростной памяти (HBM), что ограничивает их производительность в ИИ и других задачах. Однако новая технология позволит компаниям расширять объем памяти GPU, подключая дополнительную память через шину PCIe, а не ограничиваясь встроенной памятью GPU. Panmnesia — компания, поддерживаемая южнокорейским исследовательским институтом KAIST, разработала низколатентный CXL IP, который может использоваться для расширения памяти GPU с помощью CXL-расширителей памяти.
Требования к памяти для обучения ИИ на более сложных наборах данных быстро растут, что вынуждает компании либо покупать новые GPU, либо использовать менее сложные наборы данных, либо использовать память CPU в ущерб производительности. Хотя CXL — это протокол, работающий поверх PCIe-соединения, его интеграция в GPU сталкивается с рядом проблем, включая отсутствие логической структуры CXL и подсистем, поддерживающих конечные точки DRAM и/или SSD в GPU.
Для решения этой проблемы Panmnesia разработала корневой комплекс (RC), совместимый с CXL 3.1, оснащенный несколькими корневыми портами (RP), которые поддерживают внешнюю память через PCIe, и хост-мостом с декодером памяти, управляемой хостом (HDM), который подключается к системной шине GPU. Декодер HDM по сути заставляет подсистему памяти GPU "думать", что она имеет дело с системной памятью, но на самом деле подсистема использует DRAM или NAND, подключенные через PCIe.
Решение прошло обширное тестирование, показав двузначную наносекундную задержку в обе стороны, включая время, необходимое для преобразования протокола между стандартными операциями с памятью и передачами CXL flit. Оно было успешно интегрировано как в расширители памяти, так и в прототипы GPU/CPU на уровне аппаратного RTL, демонстрируя совместимость с различным оборудованием.
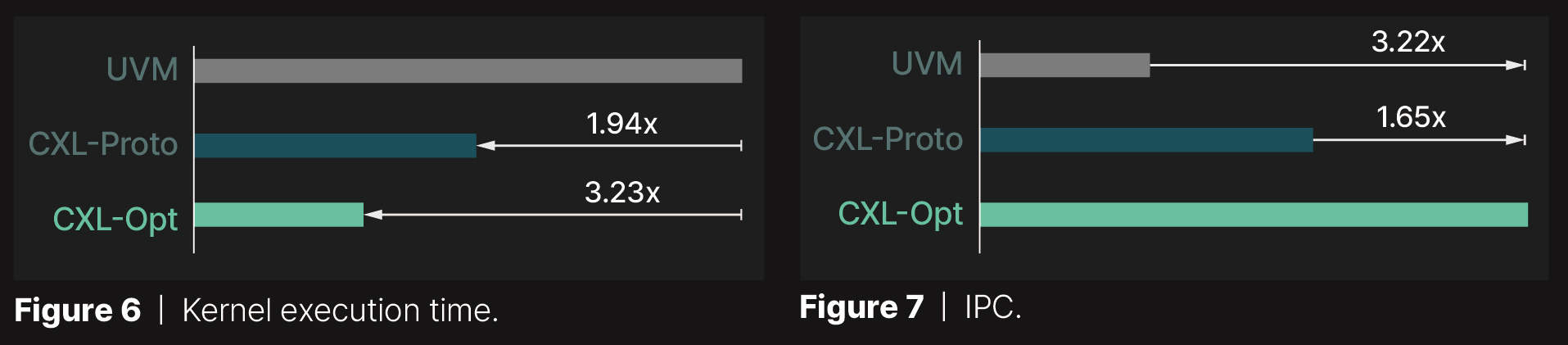
Тесты показали, что UVM работает хуже всего среди всех протестированных ядер GPU. При этом, CXL обеспечивает прямой доступ к расширенному хранилищу через инструкции загрузки/сохранения, устраняя эти проблемы.
В результате, время выполнения CXL-Proto в 1,94 раза короче, чем у UVM. CXL-Opt от Panmnesia дополнительно сокращает время выполнения в 1,66 раза, а оптимизированный контроллер достигает двузначной наносекундной задержки и минимизирует задержку чтения/записи. Это также отражается в значениях IPC, зарегистрированных во время выполнения ядра GPU, где CXL-Opt от Panmnesia достигает производительности в 3,22 и 1,65 раза быстрее, чем UVM и CXL-Proto соответственно.


